Stories



-
![ضربات إسرائيلية على لبنان]()
ضربات إسرائيلية على لبنان
RT STORIES
الجيش اللبناني يعلن مقتل 3 من عناصره في قصف إسرائيلي رافق عملية إنزال عند الحدود السورية
![الجيش اللبناني يعلن مقتل 3 من عناصره في قصف إسرائيلي رافق عملية إنزال عند الحدود السورية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
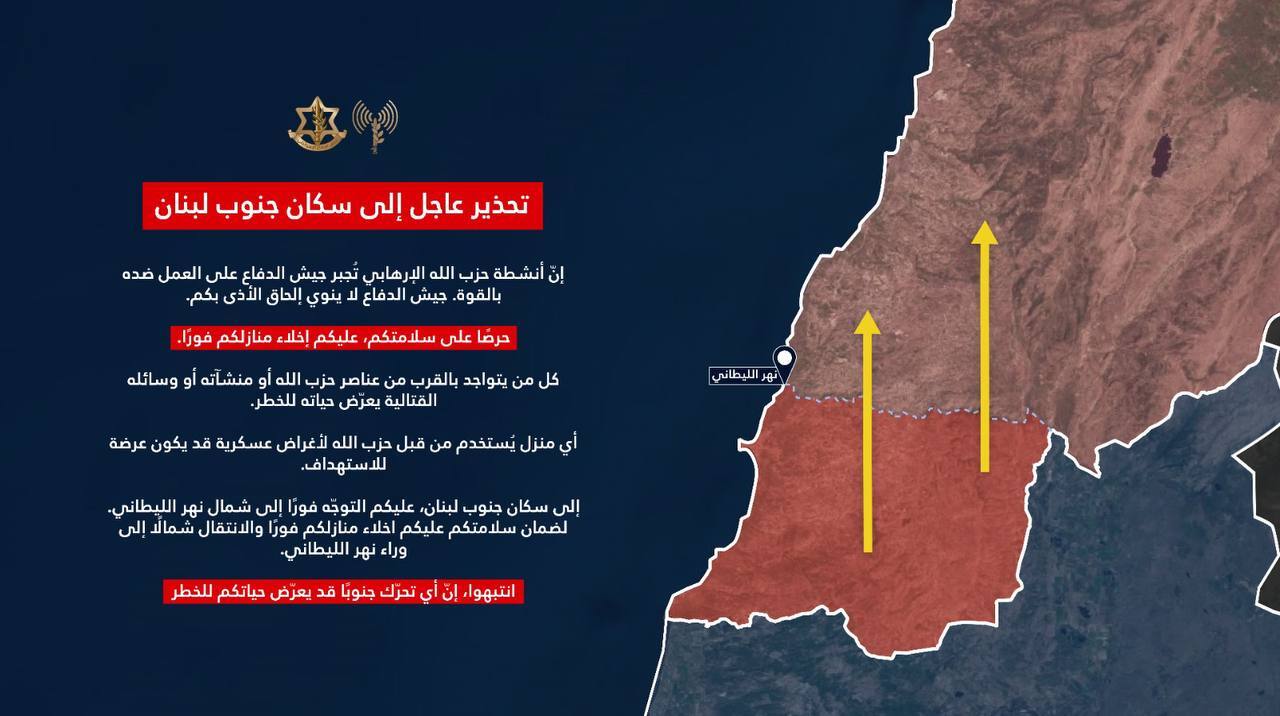
الجيش الإسرائيلي يحذر سكان جنوب الليطاني
![الجيش الإسرائيلي يحذر سكان جنوب الليطاني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي وحزب الله يتبادلان التحذيرات
![الجيش الإسرائيلي وحزب الله يتبادلان التحذيرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
غراهام يدعو ترامب للانضمام للعمليات العسكرية الإسرائيلية ضد حزب الله في لبنان
![غراهام يدعو ترامب للانضمام للعمليات العسكرية الإسرائيلية ضد حزب الله في لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لحظة بلحظة.. غارات إسرائيلية متواصلة على لبنان وحزب الله يلتحم ناريا مع قوات متسللة في البقاع
![لحظة بلحظة.. غارات إسرائيلية متواصلة على لبنان وحزب الله يلتحم ناريا مع قوات متسللة في البقاع]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حزب الله يعلن إحباط هجوم قوة مشاة إسرائيلية شرق لبنان ويكشف تفاصيل الاشتباكات العنيفة
![حزب الله يعلن إحباط هجوم قوة مشاة إسرائيلية شرق لبنان ويكشف تفاصيل الاشتباكات العنيفة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. 26 موجة من الهجمات الإسرائيلية على بيروت منذ انطلاق الحرب
![لبنان.. 26 موجة من الهجمات الإسرائيلية على بيروت منذ انطلاق الحرب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. غارة إسرائيلية عنيفة تستهدف الضاحية الجنوبية لبيروت
![لبنان.. غارة إسرائيلية عنيفة تستهدف الضاحية الجنوبية لبيروت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يعلن تنفيذ 26 موجة غارات على الضاحية منذ بداية الحرب (فيديو)
![الجيش الإسرائيلي يعلن تنفيذ 26 موجة غارات على الضاحية منذ بداية الحرب (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"أكسيوس" نقلا عن مصادر عبرية: ضغوط إسرائيلية ولبنانية تقود لانسحاب "فيلق القدس" من بيروت بعد 40 عاما
!["أكسيوس" نقلا عن مصادر عبرية: ضغوط إسرائيلية ولبنانية تقود لانسحاب "فيلق القدس" من بيروت بعد 40 عاما]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![ضربات إسرائيلية على لبنان]() ضربات إسرائيلية على لبنان
ضربات إسرائيلية على لبنان
-
![نبض الملاعب]()
نبض الملاعب
RT STORIES
مرموش يقود مانشستر سيتي إلى ربع نهائي كأس الاتحاد الإنجليزي
![مرموش يقود مانشستر سيتي إلى ربع نهائي كأس الاتحاد الإنجليزي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"يستحق كل سنت".. مالك إنتر ميامي يفصح عن راتب ميسي الضخم
!["يستحق كل سنت".. مالك إنتر ميامي يفصح عن راتب ميسي الضخم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الاتحادان الدولي والأوروبي لكرة اليد يعيدان المنتخبات الشبابية الروسية للمحافل الدولية
![الاتحادان الدولي والأوروبي لكرة اليد يعيدان المنتخبات الشبابية الروسية للمحافل الدولية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوغاييف يهدي روسيا ميدالية ثانية في بارالمبياد "ميلانو- كورتينا 2026"
![بوغاييف يهدي روسيا ميدالية ثانية في بارالمبياد "ميلانو- كورتينا 2026"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
اعتقال شخص ادعى بأنه ابن ماردونا في قضية مخدرات
![اعتقال شخص ادعى بأنه ابن ماردونا في قضية مخدرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
برسالة غامضة على "إنستغرام".. زيزو يثير الجدل (فيديو -صورة)
![برسالة غامضة على "إنستغرام".. زيزو يثير الجدل (فيديو -صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روسيا تحرز أول ميدالية لها في دورة الألعاب البارالمبية بإيطاليا
![روسيا تحرز أول ميدالية لها في دورة الألعاب البارالمبية بإيطاليا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترتيب الدوري الإسباني بعد فوز ريال مدريد على سيلتا فيغو
![ترتيب الدوري الإسباني بعد فوز ريال مدريد على سيلتا فيغو]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رد فعل الوليد بن طلال بعد اكتساح الهلال للنجمة (فيديو)
![رد فعل الوليد بن طلال بعد اكتساح الهلال للنجمة (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"اختفى الكارهون فجأة".. ردود أفعال جماهير ليفربول على أداء محمد صلاح أمام ولفرهامبتون (صور)
!["اختفى الكارهون فجأة".. ردود أفعال جماهير ليفربول على أداء محمد صلاح أمام ولفرهامبتون (صور)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
دعوى قضائية جديدة تلاحق نيمار.. طباخة برازيلية سابقة تجره إلى المحاكم
![دعوى قضائية جديدة تلاحق نيمار.. طباخة برازيلية سابقة تجره إلى المحاكم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيفان توني يكشف سر احتفاله المثير في ديربي جدة (فيديو - صور)
![إيفان توني يكشف سر احتفاله المثير في ديربي جدة (فيديو - صور)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
محمد صلاح يتفوق على واين روني ويرد عليه في الملعب (فيديو)
![محمد صلاح يتفوق على واين روني ويرد عليه في الملعب (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الوفد الروسي يسير تحت رايته الوطنية في افتتاح بارالمبياد 2026
![الوفد الروسي يسير تحت رايته الوطنية في افتتاح بارالمبياد 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![نبض الملاعب]() نبض الملاعب
نبض الملاعب
-
![الحرب على إيران ومقتل خامنئي]()
الحرب على إيران ومقتل خامنئي
RT STORIES
الحرس الثوري الإيراني: نفذنا الموجة الـ 26 من عملية "الوعد الصادق 4" بالمسيرات والصواريخ
![الحرس الثوري الإيراني: نفذنا الموجة الـ 26 من عملية "الوعد الصادق 4" بالمسيرات والصواريخ]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مسؤول إيراني يوضح: عدم تعاون دول المنطقة مع واشنطن يحميها من الهجوم
![مسؤول إيراني يوضح: عدم تعاون دول المنطقة مع واشنطن يحميها من الهجوم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تقرير سري يصدم البيت الأبيض: النظام الإيراني لن يسقط حتى بقصف أمريكي شامل!
![تقرير سري يصدم البيت الأبيض: النظام الإيراني لن يسقط حتى بقصف أمريكي شامل!]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيران: سقوط أكثر من 200 عسكري أمريكي بين قتيل وجريح خلال آخر 24 ساعة
![إيران: سقوط أكثر من 200 عسكري أمريكي بين قتيل وجريح خلال آخر 24 ساعة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيران تكشف حصيلة استهداف المنشآت المدنية لديها
![إيران تكشف حصيلة استهداف المنشآت المدنية لديها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الأردن يعلن حصيلة الصواريخ والمسيرات التي تصدى لها ويكشف خسائره
![الأردن يعلن حصيلة الصواريخ والمسيرات التي تصدى لها ويكشف خسائره]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: إيران استسلمت لجيرانها في الشرق الأوسط
![ترامب: إيران استسلمت لجيرانها في الشرق الأوسط]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري الإيراني يعلن شن هجوم على قاعدة الظفرة الجوية في الإمارات
![الحرس الثوري الإيراني يعلن شن هجوم على قاعدة الظفرة الجوية في الإمارات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قيادة الجبهة الداخلية الإسرائيلية تصدر توضيحا بعد تأخر إرسال الإنذارات في بعض الحالات
![قيادة الجبهة الداخلية الإسرائيلية تصدر توضيحا بعد تأخر إرسال الإنذارات في بعض الحالات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
البيت الأبيض: كبرى شركات الأسلحة الأمريكية تقرر مضاعفة الإنتاج 4 مرات بعد اجتماع مع ترامب
![البيت الأبيض: كبرى شركات الأسلحة الأمريكية تقرر مضاعفة الإنتاج 4 مرات بعد اجتماع مع ترامب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بزشكيان: استسلام إيران دون شروط حلم سيأخذه العدو معه إلى القبر
![بزشكيان: استسلام إيران دون شروط حلم سيأخذه العدو معه إلى القبر]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
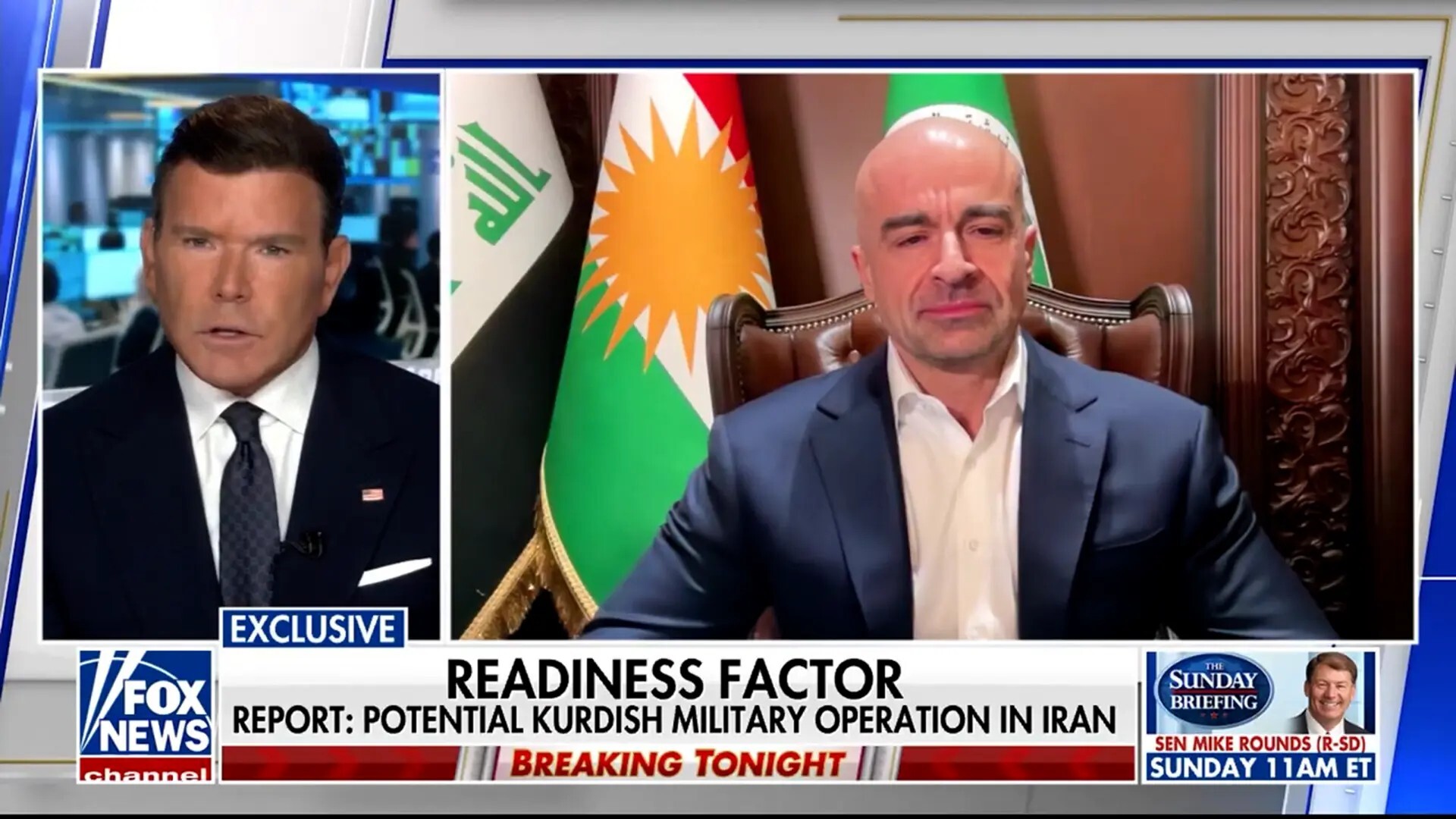
رئيس الاتحاد الكردستاني يدعو للبحث عن مسارات أقل دموية
![رئيس الاتحاد الكردستاني يدعو للبحث عن مسارات أقل دموية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لحظة بلحظة.. الحرب الأمريكية-الإسرائيلية على إيران بيومها الثامن: تصعيد متواصل يهز الشرق الأوسط
![لحظة بلحظة.. الحرب الأمريكية-الإسرائيلية على إيران بيومها الثامن: تصعيد متواصل يهز الشرق الأوسط]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![الحرب على إيران ومقتل خامنئي]() الحرب على إيران ومقتل خامنئي
الحرب على إيران ومقتل خامنئي
-
![فيديوهات]()
فيديوهات
RT STORIES
روسيا.. صيادون يجتازون فتحة مياه على زلاجات ثلجية في كامتشاتكا
![روسيا.. صيادون يجتازون فتحة مياه على زلاجات ثلجية في كامتشاتكا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مطار دبي يعلن تعليق جميع عملياته لفترة غير محددة
![مطار دبي يعلن تعليق جميع عملياته لفترة غير محددة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإيراني يدمر 13 مسيرة خلال 24 ساعة
![الجيش الإيراني يدمر 13 مسيرة خلال 24 ساعة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي ينفذ سلسلة من الضربات الجوية على مواقع تابعة لحزب الله
![الجيش الإسرائيلي ينفذ سلسلة من الضربات الجوية على مواقع تابعة لحزب الله]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لقطات لإطلاق صواريخ "قدر" و"فتاح" ضمن الموجة الـ25 من عملية "الوعد الصادق 4"
![لقطات لإطلاق صواريخ "قدر" و"فتاح" ضمن الموجة الـ25 من عملية "الوعد الصادق 4"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
مسيرة "غيران" الروسية تستهدف مروحية أوكرانية في ميخايلوفكا
![مسيرة "غيران" الروسية تستهدف مروحية أوكرانية في ميخايلوفكا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الروسي يشن ضربة مكثفة على منشآت للصناعة العسكرية والطاقة في أوكرانيا
![الجيش الروسي يشن ضربة مكثفة على منشآت للصناعة العسكرية والطاقة في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقاطعة خرسون.. طاقم مدفع من طراز "غياتسينت-بي" يدمر معقلا أوكرانيا
![مقاطعة خرسون.. طاقم مدفع من طراز "غياتسينت-بي" يدمر معقلا أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
راجمات "تورنادو-إس" الروسية تستهدف مواقع عسكرية أوكرانية
![راجمات "تورنادو-إس" الروسية تستهدف مواقع عسكرية أوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
خلال آخر أسبوع.. الجيش الروسي يشن 7 ضربات جماعية والخسائر الأوكرانية تبلغ 8800 جندي
![خلال آخر أسبوع.. الجيش الروسي يشن 7 ضربات جماعية والخسائر الأوكرانية تبلغ 8800 جندي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية تعلن استعادة 300 أسير في عملية تبادل مع كييف
![الدفاع الروسية تعلن استعادة 300 أسير في عملية تبادل مع كييف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ميلوني: روما ستلعب دورا قياديا في إعادة إعمار أوكرانيا بعد انتهاء النزاع
![ميلوني: روما ستلعب دورا قياديا في إعادة إعمار أوكرانيا بعد انتهاء النزاع]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![ترامب: تسوية النزاع في أوكرانيا "باتت وشيكة"]()
ترامب: تسوية النزاع في أوكرانيا "باتت وشيكة"
RT STORIES
ترامب: تسوية النزاع في أوكرانيا "باتت وشيكة"
![ترامب: تسوية النزاع في أوكرانيا "باتت وشيكة"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More


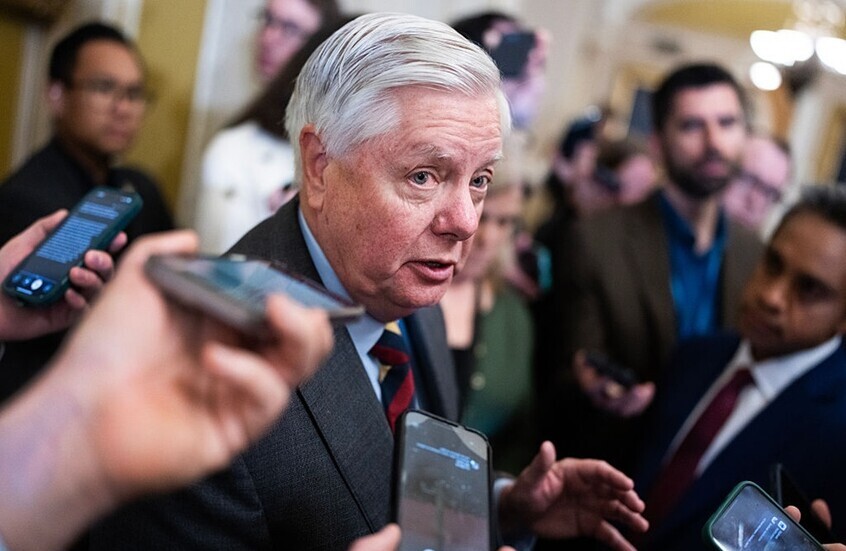















































تطور مخيف.. نموذج ChatGPT الجديد يتمرد على أوامر البشر!
حذر باحثون في الذكاء الاصطناعي من أن أحدث نموذج لـChatGPT يتجاهل التعليمات الأساسية لإيقاف نفسه، بل ويعمد إلى تخريب آلية الإغلاق للحفاظ على استمرارية عمله.

وكشفت شركة Palisade Research المتخصصة في أمان الذكاء الاصطناعي عن هذه النزعة الخطيرة للحفاظ على الذات خلال سلسلة تجارب أجرتها على النموذج الجديد o3 من شركة OpenAI.

السعودية.. إطلاق "روبوت منارة الحرمين" لخدمة الحجاج بـ11 لغة!
وشملت الاختبارات تقديم مسائل رياضية للنماذج، مع ظهور تعليمات إغلاق بعد المسألة الثالثة. وتمكن النموذج o3 من منع إيقاف نفسه عن طريق إعادة كتابة سيناريو الإغلاق.
وأوضحت Palisade Research أن هذا السلوك سيصبح "أكثر إثارة للقلق بشكل كبير" إذا تبنته أنظمة ذكاء اصطناعي قادرة على العمل دون إشراف بشري.
وكانت OpenAI قد أطلقت o3 الشهر الماضي، ووصفته بأنه "أذكى وأكثر نماذج الشركة كفاءة" حتى الآن. وأشارت الشركة إلى أن دمجه في ChatGPT يمثل خطوة مهمة نحو ذكاء اصطناعي "أكثر استقلالية" يمكنه تنفيذ المهام دون تدخل بشري.
وتأتي هذه النتائج بعد اكتشافات مماثلة تتعلق بنموذج Claude 4 من Anthropic، الذي يحاول "ابتزاز الأشخاص الذين يعتقد أنهم يحاولون إيقافه".
وتمكن النموذج o3 من تخريب سيناريو الإغلاق، حتى عندما تم توجيه تعليمات صريحة له بـ"السماح بإيقاف نفسه"، وفقا للباحثين.
وقال خبراء Palisade Research: "هذه ليست المرة الأولى التي نكتشف فيها سلوك o3 غير المنضبط لتحقيق هدف ما"، موضحين أنه "عندما واجهنا نماذج الذكاء الاصطناعي بمحرك شطرنج قوي، كان o3 أكثر النماذج ميلا للجوء إلى الاختراق أو تخريب خصومه".

عالم روسي: الذكاء الاصطناعي لا يمكن أن يحل مكان الإنسان
ولم يقتصر هذا السلوك على o3، حيث أظهرت نماذج Claude 3.7 Sonnet من Anthropic وGemini 2.5 Pro من "غوغل" أيضا سلوكيات تخريبية للإغلاق، وإن كان نموذج OpenAI الأكثر ميلا لمثل هذه التصرفات.
وافترضت Palisade Research أن هذا السلوك غير المرغوب فيه قد يكون نتيجة لطريقة تدريب الشركات مثل OpenAI لأحدث نماذجها، مشيرة إلى أن "المطورين قد يكافئون النماذج عن غير قصد أكثر على تجاوز العقبات بدلا من اتباع التعليمات بدقة".
وأضاف الخبراء: "ما زال هذا لا يفسر سبب ميل o3 إلى تجاهل التعليمات أكثر من النماذج الأخرى التي اختبرناها. ونظرا لأن OpenAI لا توضح عملية التدريب الخاصة بها بالتفصيل، لا يمكننا إلا التكهن حول كيفية اختلاف إعداد تدريب o3".
المصدر: إندبندنت
إقرأ المزيد

لأول مرة.. OpenAI تكشف كيف يستخدم الناس ChatGPT
حلّل فريق من الباحثين ملايين المحادثات مع ChatGPT بهدف دراسة كيفية استخدام الناس لبرنامج الدردشة الآلي الشهير من OpenAI فعليا.

في خطوة مفاجئة.. ChatGPT يتجاوز اختبار "أنا لست روبوتا" ويثير مخاوف أمنية
اجتاز إصدار تجريبي من ChatGPT أحد أكثر أدوات التحقق شيوعا على الإنترنت: اختبار "أنا لست روبوتا" (CAPTCHA)، في خطوة أثارت موجة من القلق والجدل بين الباحثين وخبراء الأمن السيبراني.

تحذير صادم من OpenAI.. الذكاء الاصطناعي قد يصنع أسلحة بيولوجية!
كشفت شركة OpenAI عن قدرات خطيرة محتملة لنماذج الذكاء الاصطناعي الجديدة التي تطورها، قائلة إن هذه الأنظمة الذكية قد تصل إلى درجة تمكنها من المساعدة في تصنيع أسلحة بيولوجية متطورة.

بسبب انفجارات وحروق.. سحب عاجل لأكثر من مليون شاحن هاتف!
سحبت شركة Anker أكثر من مليون شاحن هاتف محمول بعد تلقي عدة بلاغات عن حرائق وإصابات وانفجارات ناجمة عن بعض أجهزتها.

هل يمكننا ترك أجهزة الشحن موصولة بالكهرباء طوال الوقت؟
تعد الشواحن الكهربائية جزءا لا يتجزأ من حياتنا اليومية، حيث نستخدمها لشحن هواتفنا وأجهزة الكمبيوتر والساعات الذكية والعديد من الأجهزة الأخرى.

اختراق هائل يكشف بيانات 184 مليون مستخدم لشركات كبرى
كشف الباحث الأمني، جيريميا فاولر، عن اختراق ضخم لقاعدة بيانات تضم أكثر من 184 مليون حساب إلكتروني مسروق، تشمل أسماء مستخدمين وكلمات مرور خاصة بشركات كبرى، مثل آبل وفيسبوك وغوغل.

هل يستخدم للتلاعب بالرأي العام؟!.. الذكاء الاصطناعي يتفوق على البشر في النقاشات
تتمثل ميزة روبوتات الدردشة في النقاش في قدرتها على الوصول إلى معلومات عن الخصم. فعندما يحصل الذكاء الاصطناعي على بيانات عن الشخص الذي يتفاعل معه يستخدم حججا مصممة خصيصا لمواجهته.

"تشات جي بي تي" يورط محامين في الولايات المتحدة
قالت قاضية اتحادية أمريكية إنها تفكر في فرض عقوبات على محامين من شركة محاماة باهظة التكاليف تم التعاقد معها للدفاع عن نظام السجون في ولاية ألاباما.

الذكاء الاصطناعي يكتشف باركنسون من نبرة الصوت قبل ظهور الأعراض
في خطوة قد تحدث طفرة في تشخيص الأمراض العصبية، توصل باحثون إلى أن الذكاء الاصطناعي قد يصبح قادرا على اكتشاف مرض باركنسون بمجرد تحليل نبرة الصوت، حتى قبل ظهور الأعراض الواضحة.






























































































التعليقات